Self-Supervised Learning by Cross-Modal Audio-Video Clustering
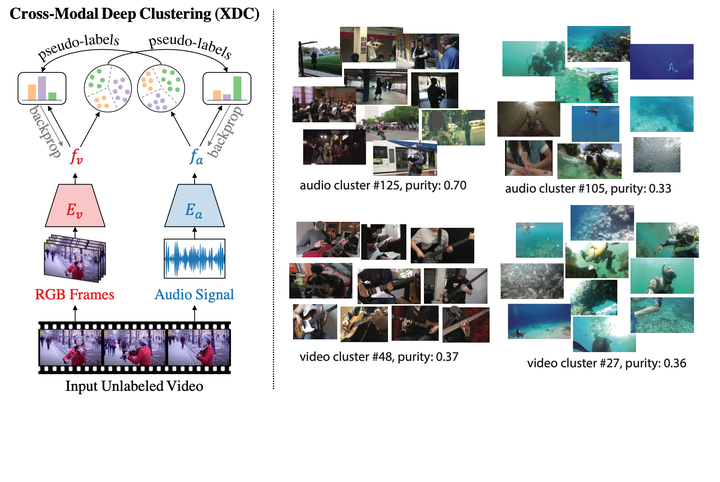 Cross-Modal Deep Clustering (XDC) is a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). Left: an overview of XDC model. Right: Visualization of XDC clusters on Kinetics videos. We visualize the the closest videos to the cluster centroid of the top-2 audio clusters (top right) and the top-2 video clusters (bottom right) in terms of purity with respect to the original Kinetics labels.
Cross-Modal Deep Clustering (XDC) is a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). Left: an overview of XDC model. Right: Visualization of XDC clusters on Kinetics videos. We visualize the the closest videos to the cluster centroid of the top-2 audio clusters (top right) and the top-2 video clusters (bottom right) in terms of purity with respect to the original Kinetics labels.
Abstract
Visual and audio modalities are highly correlated, yet they contain different information. Their strong correlation makes it possible to predict the semantics of one from the other with good accuracy. Their intrinsic differences make cross-modal prediction a potentially more rewarding pretext task for self-supervised learning of video and audio representations compared to within-modality learning. Based on this intuition, we propose Cross-Modal Deep Clustering (XDC), a novel self-supervised method that leverages unsupervised clustering in one modality (e.g., audio) as a supervisory signal for the other modality (e.g., video). This cross-modal supervision helps XDC utilize the semantic correlation and the differences between the two modalities. Our experiments show that XDC outperforms single-modality clustering and other multi-modal variants. XDC achieves state-of-the-art accuracy among self-supervised methods on multiple video and audio benchmarks. Most importantly, our video model pretrained on large-scale unlabeled data significantly outperforms the same model pretrained with full-supervision on ImageNet and Kinetics for action recognition on HMDB51 and UCF101. To the best of our knowledge, XDC is the first self-supervised learning method that outperforms large-scale fully-supervised pretraining for action recognition on the same architecture.
BibTex
@inproceedings{alwassel_2020_xdc,
title={Self-Supervised Learning by Cross-Modal Audio-Video Clustering},
author={Alwassel, Humam and Mahajan, Dhruv and Korbar, Bruno and
Torresani, Lorenzo and Ghanem, Bernard and Tran, Du},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Pretrained Model Weights
You can load all our pretrained models using torch.hub.load() API.
import torch
model = torch.hub.load('HumamAlwassel/XDC', 'xdc_video_encoder',
pretraining='r2plus1d_18_xdc_ig65m_kinetics',
num_classes=42)
Run print(torch.hub.help('HumamAlwassel/XDC', 'xdc_video_encoder')) for the model documentation, and visit our GitHub repo for more details. Learn more about PyTorch Hub here.
Visualizing XDC Clusters
We visualize the audio and visual clusters of XDC self-supervised Kinetics-pretrained model. For each cluster, we shows the 10 nearest clips to the cluster center. The lists of clusters below are ordered by clustering purity w.r.t. Kinetics labels.
Cluster # (ordered by clustering purity w.r.t. Kinetics labels)XDC Gallery
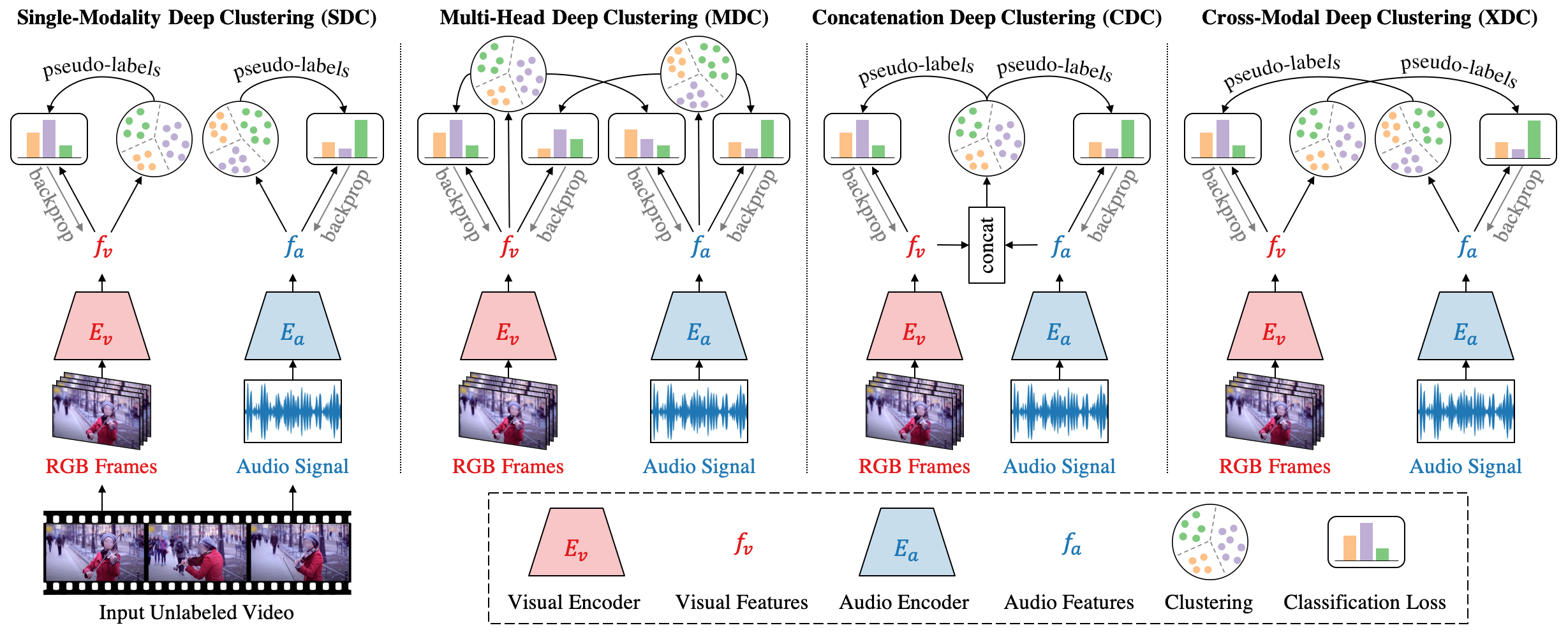
Overview of our framework. We present Single-Modality Deep Clustering (SDC) baseline vs. our three different proposed models: Multi-Head Deep Clustering (MDC), Concatenation Deep Clustering (CDC), and Cross-Modal Deep Clustering (XDC) for multi-modal deep clustering. Unlabeled videos are inputted into the video and audio encoders (E_v and E_a) to produce visual and audio features (f_v and f_a). These features, or the concatenation of them, are clustered using k-means. The cluster assignments are then used as pseudo-labels to train the two encoders. The process is started with randomly-initialized encoders, then alternates between clustering to generate pseudo-labels and training to improve the encoders. The four models employ different ways to cluster features and generate self-supervision signals for learning the visual and audio representations.
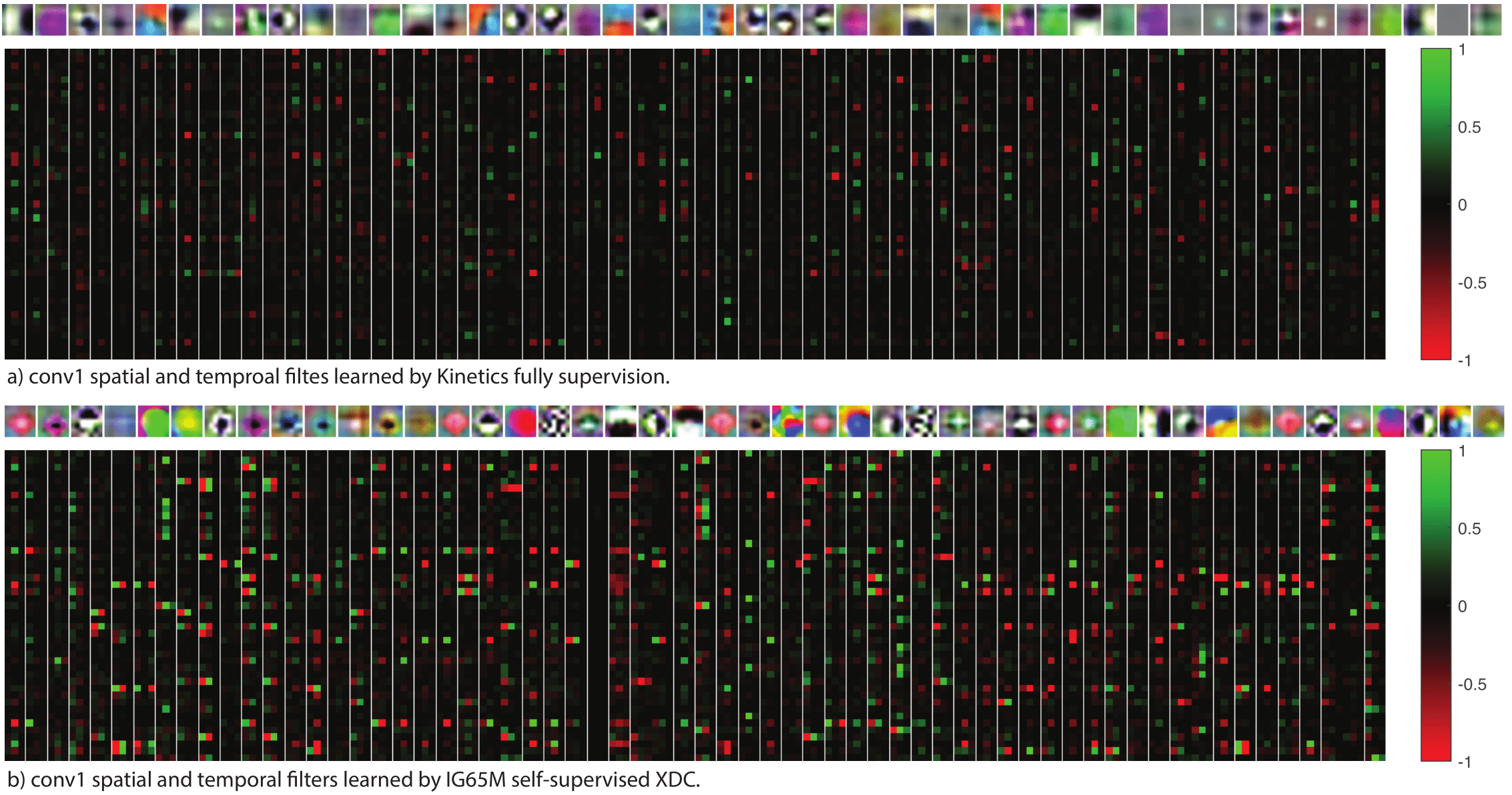
R(2+1)D filters learned with self-supervised XDC vs. fully-supervised training. (a) R(2+1)D ''conv_1'' filters learned by fully-supervised training on Kinetics. (b) The same filters learned by self-supervised XDC pretraining on IG65M. XDC learns a more diverse set of temporal filters compared to fully-supervised pretraining.